This is a Rosetta Code post.
Story
Consider the following relational database: FooDatabase
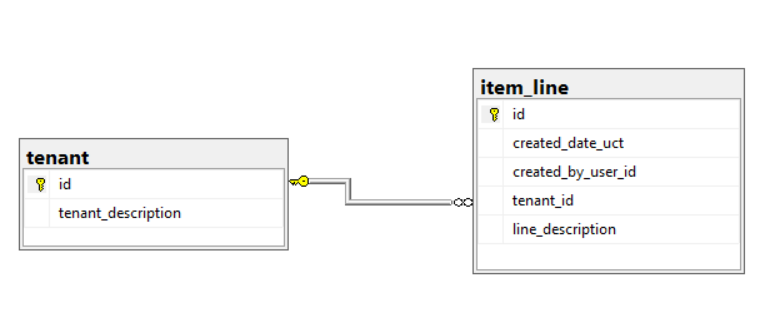
In the context of this database a tenant can only be one of App One, App Two or User. Each User has their own unique GUID and the applications have the following GUIDs:
| Application Name | GUID |
|---|---|
| App One | 3ba2e2e8-f093-41d8-8daf-64d5385604ac |
| App Two | efec5b17-47fc-4d79-ae74-6e8b023023d5 |
13 333 records in dbo.item_line have been persisted incorrectly. The column dbo.item_line.tenant_id has been populated with the GUID for App One for the period 01 Jan 2018 to 31 Dec 2018 when it should have been populated with the GUID for the User tenant. This date is stored in dbo.item_line.created_date_uct.
Thankfully dbo.item_line.created_by_user_id is a mandatory field and will contain valid user GUIDs. Note that not all users will exist in dbo.tenant.
The cleanup must be idempotent, this means it can be run multiple times without changing the result beyond the initial story/task.
Task
Cleanup the data using a SQL script in a safe manner.
- Identify all records in
dbo.item_linethat need to be updated, print the count. - Create records in
dbo.tenantthat dont exist when linking todbo.item_line.created_by_user_id, print this count too. - Update
dbo.item_line.tenant_idto be the newly createddbo.tenant.idwhen it did not exist, else update to bedbo.item_line.created_by_user_id. Print the total count of updates. This should match the first count printed.
Using the supplied data the prints and counts should be:
1 | total dbo.item_line to be updated : 13333 |
Setup
Spin up a MS SQL Instance, you can then connect to it from Microsoft SQL Server Management Studio on localhost,1500
1 | docker run --name=rosetta-df -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=Password123" -p 1500:1433 -d mcr.microsoft.com/mssql/server:2017-latest |
1 | 001 CREATE DATABASE.sql |
This should get the data into a state that matches the counts above.
Solutions
Set Operations
TLDR; A set is an exactly defined collection of objects, this can be accomplished by selecting into a #temptable.
What are set operations?
SQL set operations are a set of operations that allow you to combine or compare the results of two or more SELECT statements into a single result set. The four main SQL set operations are:UNION: The UNION operator combines the result sets of two or more SELECT statements into a single result set, eliminating any duplicates. For example, if you have two tables with the same structure and you want to combine their contents into a single table, you can use the UNION operator.
UNION ALL: The UNION ALL operator is similar to UNION, but it does not eliminate duplicates. It combines all rows from the result sets of two or more SELECT statements into a single result set.
INTERSECT: The INTERSECT operator returns the common rows between two or more SELECT statements. It returns only the rows that appear in all of the SELECT statements.
EXCEPT: The EXCEPT operator returns the rows that appear in the first SELECT statement but not in the second SELECT statement. It essentially subtracts the result set of the second SELECT statement from the result set of the first SELECT statement.
These set operations are useful for performing complex queries that involve combining or comparing data from multiple tables or views.
Cursor
TLDR; Use a STATIC cursor to iterate over the data.
What is a Cursor?
In SQL, a cursor is a database object that allows you to retrieve and manipulate a set of rows returned by a SELECT statement. A cursor is like a pointer to a specific row in the result set, which you can use to navigate through the rows one at a time and perform operations on each row.To use a cursor in SQL, you first declare it and define the SELECT statement that it will be based on. Then you open the cursor, which causes the database to execute the SELECT statement and retrieve the result set. You can then use FETCH statements to retrieve individual rows from the result set, and use UPDATE, DELETE, or other SQL statements to modify the data.
Cursors can be useful in situations where you need to iterate through a result set and perform operations on each row individually. For example, you might use a cursor to process each row of a table one at a time, performing calculations or updates on the data as you go. Cursors can also be used in stored procedures, triggers, and other database objects to perform more complex operations on data. However, it’s important to use cursors judiciously, since they can be less efficient and slower than set-based operations in SQL.
WITH common_table_expression
TLDR; Specifies a temporary named result set, known as a common table expression (CTE).
What is a common_table_expression?
A common table expression (CTE) in SQL is a named temporary result set that can be referenced within a SELECT, INSERT, UPDATE, or DELETE statement. A CTE is defined using a WITH clause, which includes a SELECT statement that defines the result set for the CTE.A CTE is similar to a subquery or derived table, but it has some distinct advantages. For example, a CTE can be referenced multiple times within the same query, making it easier to write complex queries that would otherwise require multiple subqueries or derived tables. Additionally, a CTE can improve query performance by allowing the database to reuse the result set for multiple parts of the query.
Here is an example of a simple CTE:
1 | WITH my_cte AS ( |
In this example, the CTE is defined using a SELECT statement that retrieves data from the my_table table. The result set for the CTE includes only the rows where column3 is equal to ‘some_value’. The SELECT statement that references the CTE then filters the result set further to include only the rows where column2 is greater than 100.
CTEs are a powerful feature of SQL that can simplify complex queries and improve performance. They are widely supported by most modern relational database systems, including SQL Server, MySQL, Oracle, and PostgreSQL.
References
- https://docs.microsoft.com/en-us/sql/t-sql/queries/with-common-table-expression-transact-sql?redirectedfrom=MSDN&view=sql-server-ver15
- https://docs.microsoft.com/en-us/sql/t-sql/language-elements/declare-cursor-transact-sql?view=sql-server-ver15
- https://www.sqlshack.com/understanding-the-interaction-between-set-theory-and-set-operators-in-sql-server/
- https://sqlblog.org/2012/01/26/bad-habits-to-kick-thinking-a-while-loop-isnt-a-cursor