This is a Rosetta Code post.
Story
You need to come up with a Solution Design for an Ordering System that is fault tolerant. Orders are placed by the Admin user on behalf of Customers. The customer doesnt login to anything, they place the order via E-mail/Telephonic conversation but their details are known to the company. Orders are shipped via an external company called Bobs Post but their API is unstable and can often go down for days, there is no other shipper we can use.
Task
Design a system that allows an Admin User to place orders for Customers, the actual items (what they order) dont matter. The focus is on Solution Design for a fault tolerant system where the Customer is notified when the item(s) are shipped.
Solutions
Conceptual Thinking
- Following KISS (Keep It Super Simple) solve the problem in the simplest manner, itterate later to allow for fault tolerance.
- Draft a few solutions and itterate on them
- As such use an unconventional
Sticky Noterepresentation first to show the flow - As a last draft represent as a technical sequence diagram (Miro Template)
- As such use an unconventional
- The solution is Cloud Based (Focus on AWS), consider technologies for the pending decision register item
- Security (Authentication and Authorisation), consider using OAuth2 flows
- Serverless Lamda Functions to expose data / house logic
- State Machine if we want to group logic and Lamdas
- Kubernetes (EKS) for Workers
- RESTful APIs to expose data / house logic
- Persistant storage options like Relational (RDS) or Key/Value Document DB (Dynamo)
- Frontend Application. React, Angular or Vue Single Page Application (SPA) hosted in S3
- Messaging System (SQS) and Cloud Events
- Potential Cloud Design Patterns
- Bias
- Call out and try mitigate all bias from the decision making
- Ubiquitous Language
- Figure out the language of the domain, this this in all conversations with stakeholders and the customer
- Status =
Scheduled, Shipped
First Draft
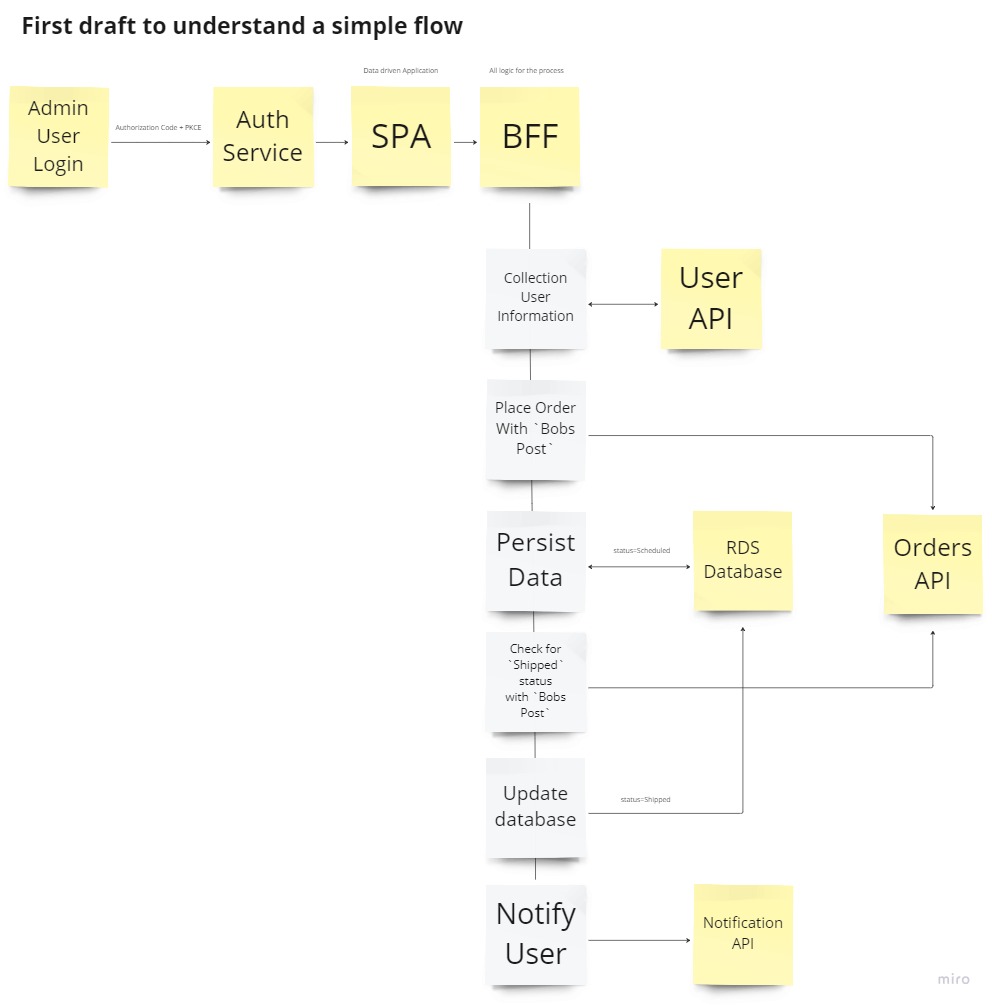
First lets understand the problem and use an unconventional Sticky Note representation.
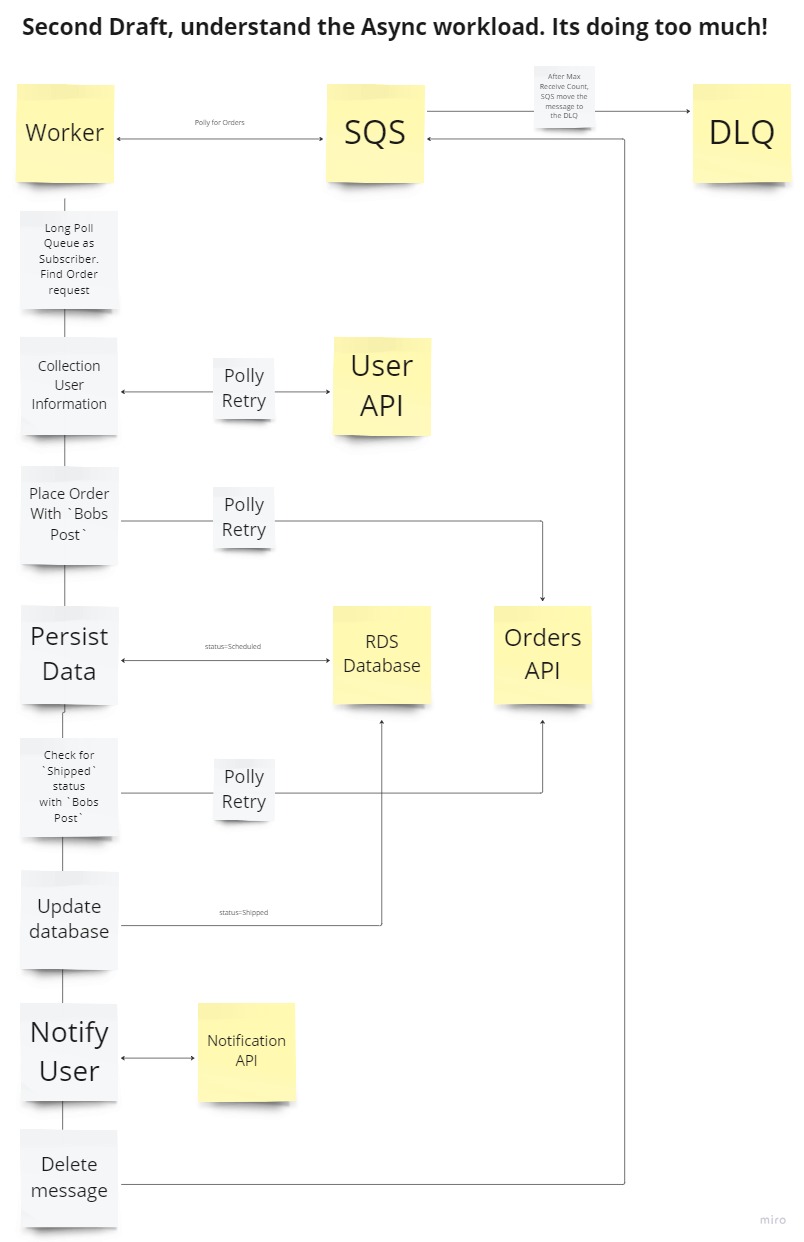
Second Draft
Remember Bobs Post has an unstable API, we can unload responsability from the BFF and introduce some retry logic using the Asynchronous Request-Reply pattern and Queues. Additionally Polly can be used to retry HTTP requests.

Now add a Worker process that will process the order request. If a message is not deleted and it has been received the maximum receive count times its pushed to the configured Dead Letter Queue (DLQ)
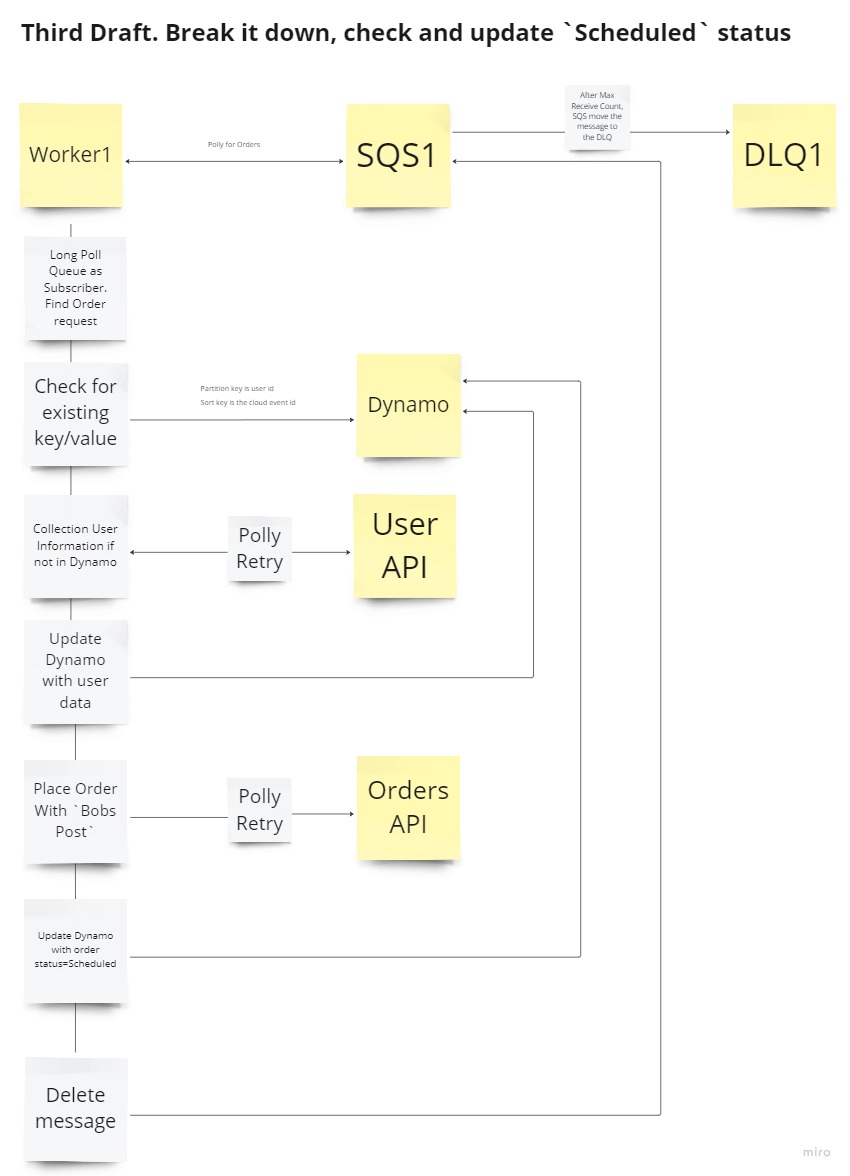
Third Draft
There is still a problem with the design as Bobs Post is unstable, so if any of the requests fail and the retry count for Polly is exhausted the process will fall over and cause possible duplication.
We can try address this by adding a key/value database like Dynamo to keep track of the process. Additionally the responsability of the process can be delegated to several workers and queues. The caveat being this brings complexity, so only introduce this when needed.
Conditional logic would be added so that should the data exist in Dynamo then dont do that step. IE: We have the user data, dont call the User API ect.
- Third Draft: The main focus here is to place the order with
Bobs Post(status=Scheduled)
- Third Draft: The main focus here is to check for updates at
Bobs Post(status=Shipped) - If no update is avalible, just Queue another message to check for shipped (WARNING: Can cause infinite loop.) So potentially just dont delete and rely on the DQL.
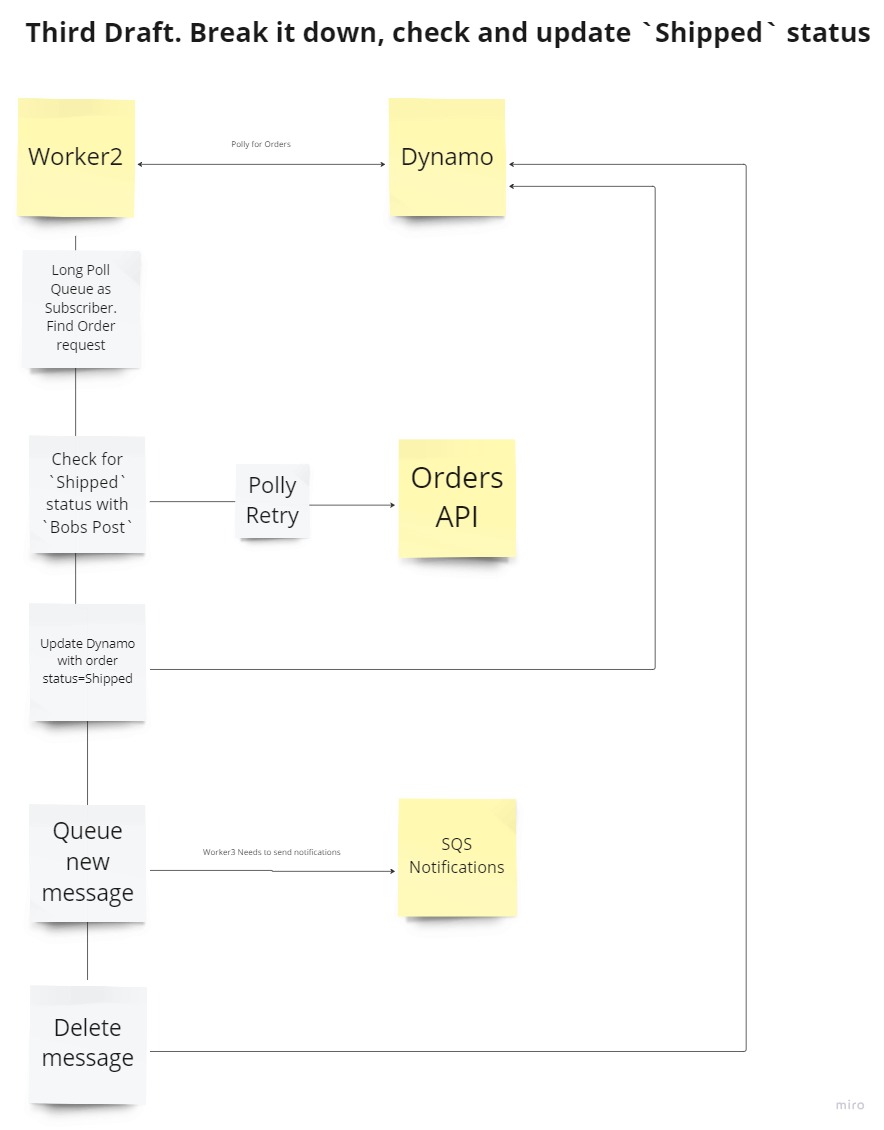
- Third Draft: The main focus here is to notify the User that their item(s) have shipped
- Emails are a common thing to send, potentially a flow exists (Event Queue) where the request can be sent
Fourth Draft
The DLQs can be redriven.
- Another worker can poll each DLQ and re-drive
- The process could be manual
Finally once you agree with your team(s) draw as a technical sequence diagram. Also see the Miro Template.
Final Thoughts
The process above is not without fault. The SQS messages default retention period is 4 days so if Bobs Post is down for longer than this and the maxium retry period is exhausted the system will fall over. Potentially the flow could be SPA -> BFF -> SQS -> DYNAMO with workers that progress the status and call the APIs based on the state of the DYNAMO database record.
My suggestion is to be pragmatic and solve problems when they are problems, if you add complexity early you could solve a problem that doesnt exist and the potential gains are lost in the complexity.